
Getting Started with Guacamole in Rails: ArangoDB Tutorial
Please note that parts of this article will not work out of the box with ArangoDB 3.0
Using ArangoDB as your main database is a good idea for various reasons. What I personally like about it is its query language AQL. I used relational databases in the past as my main database and writing statements in a language similar to SQL was a great way for me to get started with ArangoDB.
Having a HTTP based interface (like all the cool kids these days) we could build applications running solely on top of our database. That’s rather nice but then we would have to take care of all the gory details. So for our app we want at least an abstraction layer on top of the HTTP API. Better yet, something assisting us with modeling our domain logic.
Meet Guacamole: A object-document-mapper that takes care of all the busywork and allows you to focus on your domain. Since Guacamole is doing some things different than ActiveRecord, this post should give you an extensive introduction into Guacamole and demonstrate different use cases.
After reading this post you will be able to:
- Understand the core concepts of Guacamole
- Integrate ArangoDB into Rails
- Model your domain with Guacamole
About the App
To demonstrate Guacamole we will build a simple application that will recommend GitHub repositories based on the users you are following. The user model for this app is rather simple:
- A user has followings and repositories
- Followings are a list of other users
- A repository has a name and a number of watchers, stargazers and forks
One thing special about Guacamole is that it uses a graph to model relations between objects. Let’s take at the graph of our application:

As luck would have it graphs are an efficient approach to handle recommendations :wink:. The goal is to recommend repositories from our followings. As you can see in the graph above, those repositories are all neighbors with a depth of two. As I will show later translating this to a query is rather simple.
That’s the entire data model of the app — so let’s get started with the implementation. If you have worked with Rails before, you are probably familiar with ActiveRecord. I will focus on the differences between modeling with Guacamole and ActiveRecord.
Before You Start
What do you need to follow along:
- Installed ArangoDB
- Ruby 2 or higher
- A GitHub API secret and key
Installing
For the sake of simplicity we assume a blank start. Adding Guacamole to an established rails application with another DB configured is another story and will be covered in a separate post.
First things first. Let’s create a fresh Rails application without ActiveRecord:
$ rails new github-recommender -O
Now add Guacamole to the Gemfile and re-run bundle install
gem 'guacamole'
After the application has been bootstrapped we need to create our models. Guacamole is integrated into the generator system of Rails, so everything should work as expected:
$ rails generate model user name:string github_uid:fixnum github_token:string login:string
invoke guacamole
create app/models/user.rb
invoke collection
create app/collections/users_collection.rb
The file app/models/user.rb should look familiar. It defines the attributes we passed to the generator before:
# File: models/user.rb
class User
include Guacamole::Model
attribute :name, String
attribute :github_uid, Fixnum
attribute :github_token, String
attribute :login, String
end
At the bottom this is just a plain Ruby object with some magic sparkles on top to support the definition and assignment of attributes. Additionally it is fully ActiveModel compliant. But a Gucamole::Model has no idea of a database or how its attributes will be persisted at all. Interacting with the database is the responsibility of another class: UsersCollection. This class lives in the corresponding file generated earlier: app/collections/users_collection.rb. Nothing much to see here as well:
# File: collections/users_collection.rb
class UsersCollection
include Guacamole::Collection
end
At this point we can already start playing around on the console:
user = User.new name: "Pinkie Pie"
user.key #=> nil
UsersCollection.save user
user.key #=> 123414511
There are two things worth mentioning:
- Persisting the
userin the database is done byUsersCollection.saveinstead of auser.save. - The
userhas akeyinstead of anid.
As mentioned before Guacamole differs from other ORMs like ActiveRecord or Mongoid by design. Instead of relying on the active record pattern it implements a data mapper. On first glance data mapper is more complicated but I think this is mainly due to the fact we are so used to active record in the Rails world. I think in the long-run data mapper is superior to active record:
- There is separation of concern between the collection and the model.
- The model can be tested completely independent of the database.
- Breaking up large models is by far easier since the persistence layer will not be affected.
- Core concepts of ArangoDB like embedding documents are easier to realize this way.
For now the only thing you need to remember is to not call save on the model but on the collection.
Import Data from GitHub
To receive the required data from GitHub we need an authenticated access to their API or we would hit the rate limit pretty soon. The user looking for recommendations will need to allow access to publicly visible profile information (and nothing more) before proceeding to her recommendations. Since GitHub uses OAuth2 we will use Omniauth to realize this communication. If you have never worked with Omniauth before please have a look at their documentation. Setting up Omniauth will include the creation of a SessionsController where we will interact with ArangoDB directly for the first time:
# File: controllers/sessions_controller.rb
class SessionsController < ApplicationController
def create
if user = UsersCollection.update_user(auth_hash)
self.current_user = user
redirect_to recommendations_path
else
redirect_to root_path, notice: 'Something went wrong'
end
end
end
The auth_hash is just a method to transform the response from GitHub and make it usable for us. For details refer to the actual implementation. The interesting bits will happen in the UsersCollection:
# File: collections/users_collection.rb
class UsersCollection
include Guacamole::Collection
class << self
def update_user(attributes)
user = find_or_create_by_attributes(attributes)
user.attributes = user.attributes.merge(attributes)
if user.changed_attributes?
save(user)
end
user
end
def find_or_create_by_attributes(attributes)
user = by_aql("FILTER user.login == @login", login: attributes[:login]).first
return user if user.present?
new_user = User.new(attributes)
save(new_user)
end
end
end
Let’s have a closer look at what is happening here. Each user should have only one entry in the database. Since we want to import users from GitHub who can later use the app themselves we need a method to update or create a user based on certain attributes. As mentioned before ArangoDB comes with a powerful query language and Guacamole provides a simple — yet complete way to facilitate AQL. For this particular use case we just provide the filter. Everything else is done by Guacamole and the resulting query will look like this:
FOR user IN users
FILTER user.login == @login
RETURN user
Just calling by_aql will return a query instance. The query itself includes the Enumerable module so you can interact with the result like any other collection class. However the actual call to the database will not happen before you call each on the query (or any other method resulting in a call to each like first in this case).
Great! Now we can start retrieving actual data from GitHub.
To interact with the GitHub API we will use the wonderful Octokit. Just add it to your Gemfile, run bundle install and maybe get something to drink.
We will encapsulate the importing logic into a dedicated class which implements two methods: one for importing the followings and one for importing the repositories:
# File: models/github_importer.rb
class GithubImporter
def import_followings
end
def import_repositories
end
end
Let’s start with followings of a user since we don’t need to create another model for them. We just need a relation between different users. To implement this we first need to know how to implement relations in Guacamole.
Add Relations between Models
We will start with the followings of the authenticated user, so our first step is to add a new attribute to the User:
# File: models/user.rb
class User
include Guacamole::Model
attribute :followings, Array[User], coerce: false
end
Again, this is just a plain Ruby attribute. No strings attached. Just an array of users. As I mentioned before, Guacamole uses a graph to store the relations between documents: So let’s define an edge:
# File: models/followship.rb
class Followship
include Guacamole::Edge
from :users
to :users
end
This will tell ArangoDB to create an edge collection — allowing connections from user vertices to other user vertices. A user vertex is defined as a document of the users collection. You could imagine this as a has_many :through association from ActiveRecord. But where you would end up with a whole bunch of associations in ActiveRecord you only have edges in Guacamole. I believe using graphs will drastically improve the overall development experience and so I like to model them explicitly. Under the hood an instance of Guacamole::Edge is just a regular Guacamole::Model allowing us to store additional attributes in the edge (again like has_many :through associations).
Up to this point followings would just be written as an array of user documents. We now need to tell the UsersCollection to handle this particular attribute differently:
# File: collections/users_collection.rb
class UsersCollection
include Guacamole::Collection
map do
attribute :followings, via: Followship
end
end
This block is responsible for taking the array of users in the followings attribute, storing them as dedicated user documents and creating edges between the authenticated users and each of their followings. When retrieving the user, Guacamole will do the inverse.
Having taken care of that, we can now implement the import_followings method of the importer:
class GithubImporter
def import_followings
# This will get all the followings
followings = client.following.map do |following|
# We need to create user objects here
end
# Assign the followings
@user.followings = followings
# And save to the database
UsersCollection.save @user
end
end
Voila! Relations between models without adding any foreign keys. Neat. Isn’t it? 😉
Importing the Repositories
Having followings is only one piece in this puzzle. What we need are repositories. Since that’s what we want to recommend, right? But before we can flesh out the import_repositories method in the importer we need to create a Repository model, a responsible collection class and an edge model to define the relation between users and repositories.
Let’s generate the model and collection class first:
$ rails generate model repository name:string stargazers:fixnum watchers:fixnum forks:fixnum language:string url:string
invoke guacamole
create app/models/repository.rb
invoke collection
create app/collections/repositories_collection.rb
I’ll skip the output since it is basically the same as before. Now we need to add the respective attributes to both User and Repository class:
# File: models/user.rb
class User
include Guacamole::Model
attribute :repositories, Array[Repository], coerce: false
end
Besides the user attribute we store additional information of a repository to be able to link to it and calculate a rank for recommendations:
# File: models/repository.rb
class Repository
include Guacamole::Model
attribute :user, User, coerce: false
attribute :name, String
attribute :url, String
attribute :language, String
attribute :watchers, Fixnum
attribute :stargazers, Fixnum
attribute :forks, Fixnum
attribute :rank, Fixnum
end
We need to tell the collection classes how to handle the relational attributes:
# File: collections/repositories_collection.rb
class RepositoriesCollection
include Guacamole::Collection
map do
attribute :user, via: Ownership, inverse: true
end
end
# File: collections/users_collection.rb
class UsersCollection
include Guacamole::Collection
map do
attribute :repositories, via: Ownership
attribute :followings, via: Followship
end
end
As before we need to define the edge which will be used to realize the relation between a user and her repositories. In this case I named the edge Ownership since that is all this relation is about. At this point you can probably image other, more sophisticated ways of modeling the relation between users and repositories but let’s keep it simple for now:
# File: models/ownership.rb
class Ownership
include Guacamole::Edge
from :users
to :repositories
end
Having ownerships we can actually import repositories from GitHub:
class GithubImporter
def import_repositories(user)
user.repositories = client.repos(user.login).map do |repo|
# Another custom method to check if we already have imported this particular repo
RepositoriesCollection.find_or_initialize_by_attributes(repo)
end
UsersCollection.save user
end
end
At this point we have all the information we need to recommend something to the user. What was not shown yet is the code where the actual import is triggered. Additionally we should probably import the data in a background process since it eventually will take more time then users are willing to spent in a web request. All this will be left as an exercise for the reader. 😉
Using Graph Functions for Recommendations
Please note that GRAPH_* functions were removed with ArangoDB 3.0
Before we’ll dive right into the code let’s talk about the functionality we actually need here first:
- A model that provides access to the repository and its rank.
- An interface to initiate the graph query.
From a domain perspective a recommendation is just another model. Even though it is not persisted it is best practice to encapsulate it in a dedicated class. Including ActiveModel::Conversion lets it play nicely with the view layer of Rails and we can use it just as any other model. To simplify the code I implemented the database queries as class methods. I would recommend you go with a data mapper approach in a real world app. But enough talking, let’s have a look at the code:
# File: models/recommendation.rb
class Recommendation
include ActiveModel::Conversion
MIN_RANK = 110
DEFAULT_LANGUAGE = 'Ruby'
RECOMMENDATION_AQL = <<-AQL.strip_heredoc
FOR n IN GRAPH_NEIGHBORS(@graph,
{ _key:@vertex },
{ direction: 'outbound',
maxDepth: 2,
minDepth: 2,
vertexCollectionRestriction: 'repositories'
})
LET rank = (2*n.vertex.stargazers + n.vertex.watchers + 4*n.vertex.forks)
FILTER n.vertex.language == @language &&
rank >= @min_rank
SORT rank DESC
LIMIT 5
RETURN MERGE(n.vertex, { rank: rank })
AQL
class << self
def recommendations_for(user, language)
query_for_recommendations(user, language).map do |repo|
new(repo)
end
end
def query_for_recommendations(user, language)
RepositoriesCollection.by_aql(RECOMMENDATION_AQL, {
vertex: user.key,
min_rank: MIN_RANK,
language: language || DEFAULT_LANGUAGE,
graph: Guacamole.configuration.graph.name },
{ return_as: nil, for_in: nil })
end
end
attr_reader :repo
def initialize(repo)
@repo = repo
end
def rank
repo.rank || 0
end
end
That’s the entire implementation. Nothing left out this time. Though the really interesting bits are in the Recommendation.query_for_recommendations method. As I stated before you can use the full power of AQL from Guacamole. In this particular case we write our own RETURN and FOR ... IN part but let Guacamole still apply the mapping into Repository objects. To help you understand how the graph will be traversed, have a look at following illustration. The goal is to recommend repositories from our followings.
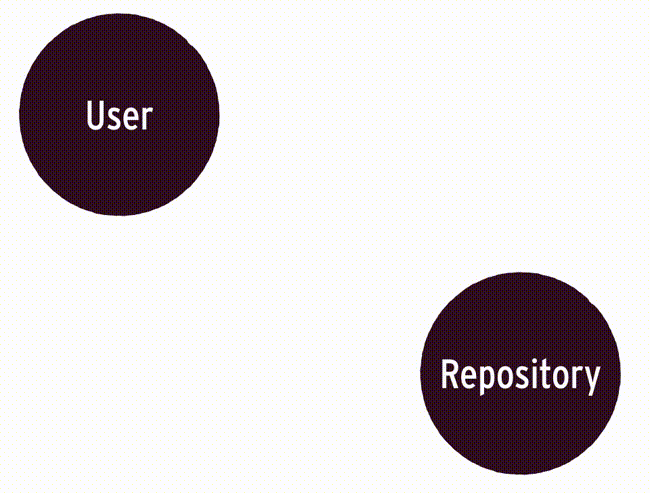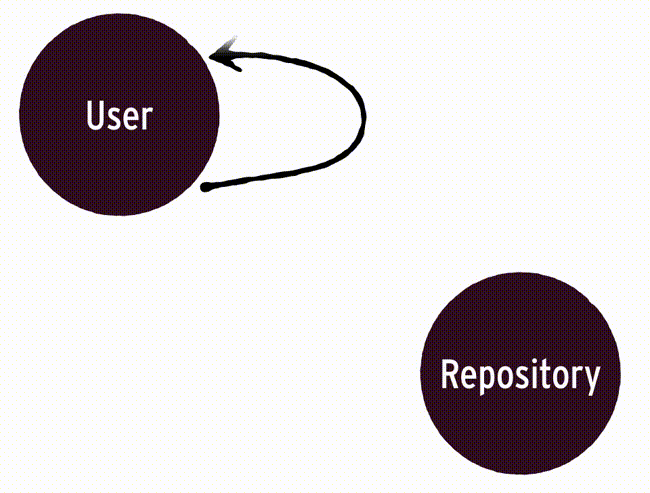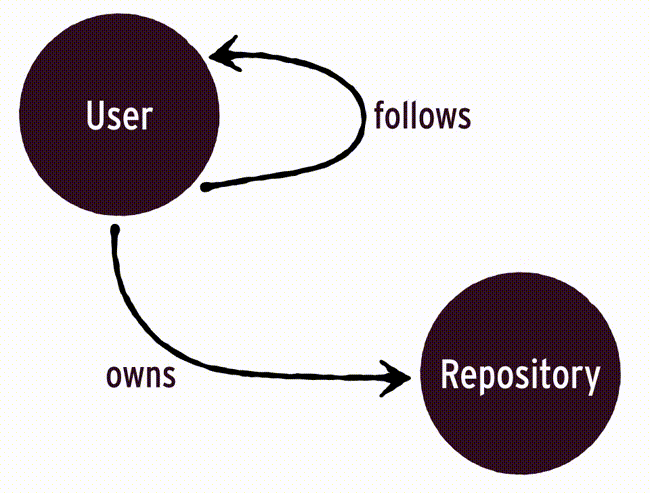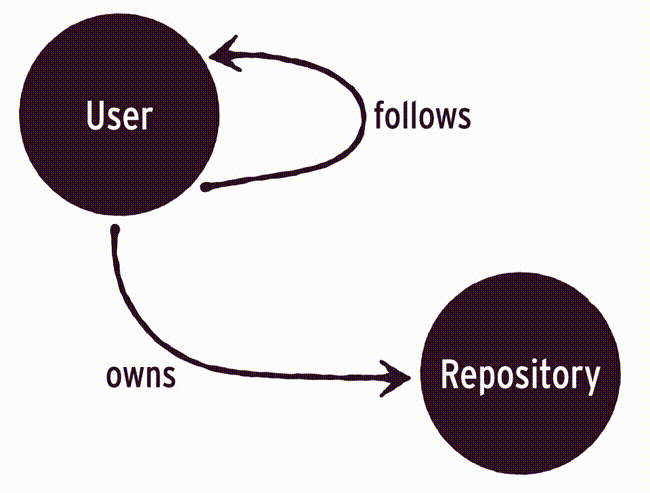
On first sight the query itself looks more intimidating then it actually is. Don’t worry, I will guide you through it step by step:
FOR n IN GRAPH_NEIGHBORS
Most of the time an AQL query will start with a FOR x IN y part. It will loop over the list y and assign the current element to variable x. In our case the list is the result of the function GRAPH_NEIGHBORS. It is one of many built in graph functions.
GRAPH_NEIGHBORS(@graph, { _key:@vertex }, { direction: 'outbound', maxDepth: 2, minDepth: 2, vertexCollectionRestriction: 'repositories' })
The GRAPH_NEIGHBORS function takes three arguments: the name of the graph, the start vertex (in our case the current user) and some options to specify the traversal. Since all graphs in ArangoDB are directed, we need to specify that we only want to follow outbound edges. We don’t want our own repositories and not the ones from the followings of our followings. Thus we will only look at neighbors at a depth of 2. Lastly we’re only interested in repositories and nothing else. Even though there is nothing else right now it is a good idea to be implicit about this.
LET rank = (2*n.vertex.stargazers + n.vertex.watchers + 4*n.vertex.forks)
For each returned repository we calculate a rank and store in a variable with LET.
FILTER n.vertex.language == @language && rank >= @min_rank
FILTER all repositories with a rank above a certain threshold and the selected primary (programming) language.
SORT rank DESC
SORT all repositories by rank
LIMIT 5
LIMIT result to 5 entries.
RETURN MERGE(n.vertex, { rank: rank })
MERGE rank in each repository document and RETURN it.
The result of this query will be an array of up to five repository objects with a populated rank (that’s why we earlier defined an attribute rank in the repository model). Congratulations and a big thank you to all who stayed until this point. The only thing left now is to display the results:
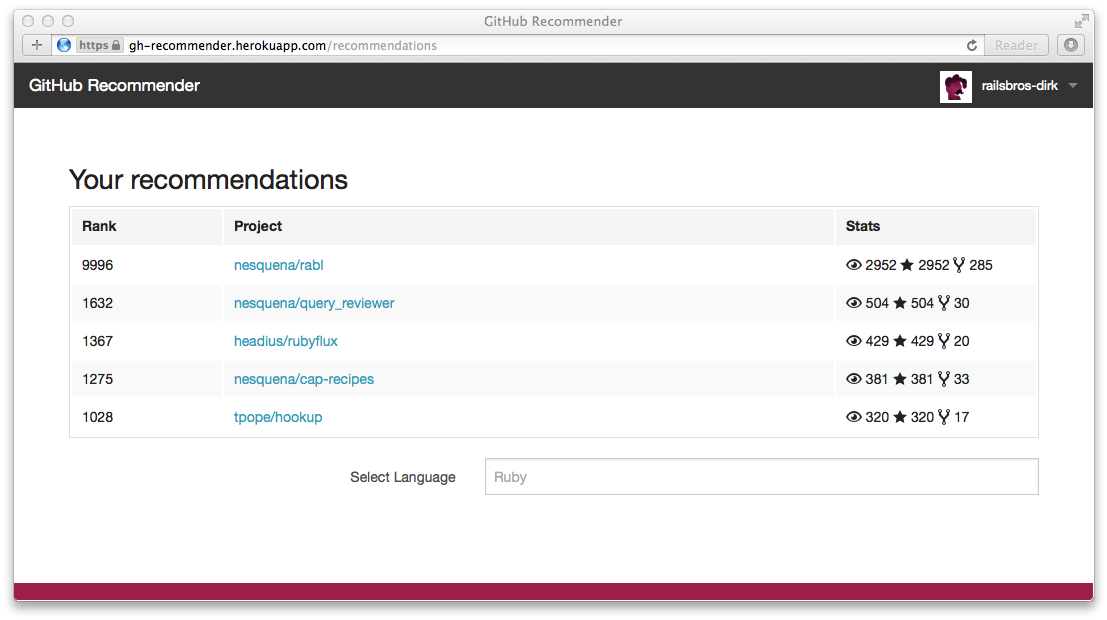
There is an old developer proverb saying “It’s nil until you ship it”. But that will left for another blog post 😉
This is the End
Even without any knowledge of AQL I think this query is easy to understand. Even such a simple traversal would be much more complicated in SQL. More common problems are equally complex but those will be handled by the ORM anyway. So it is safe to say that Guacamole and ArangoDB are a good team to improve the overall development experience in a Rails project.
I’d argue Guacamole and ArangoDB are a good team to improve the development experience in a Rails project.
Guacamole is still a relatively young project but I think the core design of it combined with the flexibility of ArangoDB make it a very interesting addition to the current Rails and Ruby ecosystem. At this point I would say Guacamole is ready to be used. There are still things missing, but the next step is to get feedback from actual users. I don’t ask you to change your entire setup (that would be crazy) — any smallish project is fine. Just give it a try! And if you happen to be on the look for an open source project to contribute: Guacamole is a friendly place to start.
That’s all folks — hope you liked it.
2 Comments
Leave a Comment
Get the latest tutorials, blog posts and news:
UsersCollection.save user does not work 🙁 Result is:
2.2.0 :018 > UsersCollection.save user
NoMethodError: undefined method `create_transaction’ for nil:NilClass
You should try to define the collection and the graph (if needed) on the web interface of arango which you can access at http://localhost:8529 .