
Do Graph Databases Scale? Yes? No? Let’s see!
Estimated reading time: 10 minutes
Graph Databases are a great solution for many modern use cases: Fraud Detection, Knowledge Graphs, Asset Management, Recommendation Engines, IoT, Permission Management … you name it.
All such projects benefit from a database technology capable of analyzing highly connected data points and their relations fast – Graph databases are designed for these tasks.
But the nature of graph data poses challenges when it comes to *buzzword alert* scalability. So why is this, and are graph databases capable of scaling? Let’s see…
In the following, we will define what we mean by scaling, take a closer look at two challenges potentially hindering scaling with graph databases and discuss solutions currently available.
What is “scalability of graph databases”?
Let’s quickly define what we mean here by scaling, as it is not “just” putting more data on one machine or throwing it on various ones. What you want when working with large or growing datasets is also an acceptable performance of your queries.
So the real question here is: Are graph databases able to provide acceptable performance when data sets grow on a single machine or even exceed its capabilities?
You might ask why this is a question in the first place. If so, please read the quick recap about graph databases below. If you are already aware of the issues like supernodes and network hops, please skip the quick recap.
Quick Recap about Graph Databases
In a nutshell, graph databases store schema free objects (vertices or nodes) where arbitrary data can be stored (properties) and relations between the objects (edges). Edges typically have a direction pointing from one object to another. Vertices and edges form a network of data points which is called a “graph”.
In discrete mathematics, a graph is defined as a set of vertices and edges. In computing it is considered an abstract data type which is really good at representing connections or relations – unlike the tabular data structures of relational database systems, which are ironically very limited in expressing relations.
As mentioned above, graphs consist of nodes aka vertices (V) connected by relations aka edges (E).

Vertices can have an arbitrary amount of edges and form paths of arbitrary depth (length of a path).
A financial transaction use case from one bank account to the other could be modeled as a graph as well and look like the schema below. Here you might define bank accounts as nodes and bank transactions among other relationships as edges.

Storing accounts and transactions in this way will enable us to traverse the created graph in unknown or varying depth. Composing and running such queries in relational databases tends to be a complex endeavor. (Sidenote: As ArangoDB is a multi-model database, we could also model the relationship between banks and their branches as a simple relation using joins to query). Check out this course to learn more about graph databases.
Graph databases provide various algorithms to query stored data and analyze relationships. Algorithms may include query capabilities like traversals, pattern matching, shortest path or distributed graph processing like community detection, connected components or centrality.
Most algorithms have one thing in common which is also the nature of the supernode and network hop problem. Algorithms traverse from one node via an edge to another node.
After this quick recap, let’s dive into the challenges. First off: celebrities.
Always these Celebrities
As described above, vertices or nodes can have an arbitrary amount of edges.
A classic example for the supernode problem are celebrities in a social network. A supernode is a node in a graph dataset with unusually high amounts of incoming or outgoing edges.
For instance, Sir Patrick Stewart’s Twitter account has currently over 3.4 million followers.

If we now model accounts and tweets as a graph and traverse through the dataset, we might have to traverse over Patrick Stewart’s account and the traversal algorithms would have to analyze all 3.4m edges pointing to Mr Steward’s account. This will increase the query execution time significantly and may even exceed acceptable limits. Similar problems can be found in e.g. Fraud Detection (accounts with many transactions), Network Management (large IP hubs) and other cases.
Supernodes are an inherent problem of graphs and pose challenges for all graph databases. But there are two options to minimize the impact of supernodes.
Option 1: Splitting Up Supernodes
To be more precise, we can duplicate the node “Patrick Stewart” and split up the large amount of edges by a certain attribute like the country the followers are from or some other form of grouping. Thereby, we minimize the impact of the supernode on traversal performance in case we can make use of these grouping in the queries we want to perform.
Option 2: Vertex-Centric Indexes
A vertex-centric index stores information of an edge together with information about the node.
To stay in the example of Patrick Stewart’s Twitter account, depending on the use case, we could use
- date/time information about when someone started to follow
- the country the follower is from
- follower counts of the follower
- etc.
All these attributes might provide the selectivity we need to effectively use a vertex-centric index.
The query engine can then use the index to lower the amount of linear lookups needed to perform the traversal. The same approach can be used for e.g. Fraud Detection. Here financial transactions are the edges and we could use the transaction dates or amounts for achieving high selectivity.
There are cases where using the options described above are not suitable and one has to live with some degree of performance degradation when traversing over supernodes. Yet, in most cases, there are options to optimize performance.
But there is another challenge, which hasn’t been solved by most graph databases.
The Network Hop Problem: If you tear them apart, you have to pay. Or do you?
First a quick recap. We have a highly connected dataset and need to traverse through it.
On a single instance all data needed for our query resides on the same machine loaded into main memory. A single main memory lookup takes around 100ns.
Let us now assume our dataset outgrew the capabilities of a single instance or we want the high availability of a cluster or additional processing power… or, as always, everything.
In a graph case, sharding means tearing apart what was previously connected and data needed for our graph traversal might now reside on different machines. This introduces network latency into our queries. I know network might not be a developers problem but query performance is.
Even on modern Gbit networks and servers being in the same rack, a lookup over the network is around 5000x more expensive compared to an in-memory lookup. Add a bit of load on the network connecting your cluster servers and you might even get unpredictable performance.

In this case, the traversal might start on DB Server 1 and then hit a node with an edge pointing to vertices stored on DB Server 2 leading to a lookup over the network – a network hop.
If we know think about more real world use cases, we might have multiple hops during a single traversal query.
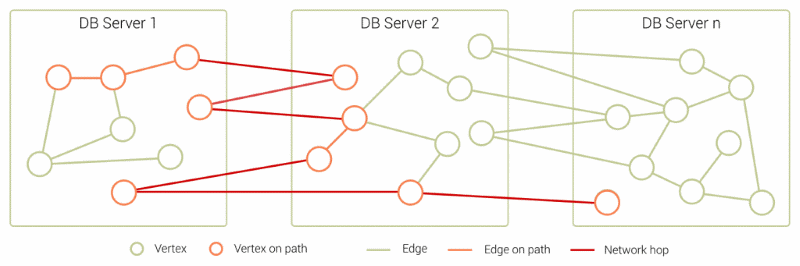
In Fraud Detection, IT Network Management or even modern Enterprise Identity and Access Management use cases, one might need to distribute graph data while still having to execute queries with sub-second performance. Multiple network hops during query execution can jeopardize this requirement, paying a high price for scaling.
There is a smarter way to approach the problem
In most cases, you already have some knowledge about your data which we can use to shard the graph in a smart way (customer IDs, geo spatial aspects, etc.). In other cases we can use distributed graph analytics generating this domain knowledge for us by using Community Detection Algorithms within e.g. ArangoDB’s Pregel Suite, calculating this domain knowledge for you.
For now, we can just do a quick thought experiment. Let’s assume we have a fraud detection use case and need to analyze financial transactions to identify fraud patterns. We know from the past that fraudsters use banks in certain countries or regions most of the time to launder their money (you can give real fraud detection queries a try on ArangoGraph, just follow the onboarding guide after sign-up).
We can use this domain knowledge as a sharding key for our graph dataset and allocate all financial transactions performed in this region on DB server 1, and distribute other transactions on other servers.

Now you can leverage the SmartGraph feature of ArangoDB to execute Anti Money Laundering or other graph queries locally and therefore avoid or, at least, greatly minimize the network hops needed during query execution. “Nice, but how?” you might ask.
The query engine within ArangoDB knows where the data needed during a graph traversal is stored, sends the query to the query engine of each DB server and processes the request locally and in parallel. The different parts of the results on each DBserver will then get merged together on the coordinator and send to the client. With this approach, SmartGraphs allow for performance characteristics close to a single instance.
If you have a rather hierarchical graph, you can also leverage the Disjoint SmartGraph Feature (coming with ArangoDB 3.7) for an even better optimization of queries.
I’d love to present also other solutions to the network hop problem but to my best knowledge there is no other. If you know about another solution, please feel free to let me know in the comments below!
Conclusion
The growing need to answer very complex questions within the enterprise and the ever growing amount of unstructured data generated by the various departments of large organizations call for a scalable solution. Graph technology is more and more used to answer these complex questions or parts of them.
We hope this article has been useful and interesting for you. We guess we can now safely say that there are options for graph databases like ArangoDB to scale vertically but also horizontally. A special feature of ArangoDB is to provide also great performance characteristics in many cases where data needs to be distributed. In the case of ArangoDB, also without changing your queries.
There are for sure some edge cases where vertex-centric-indices or SmartGraphs can’t help but these tend to be very rare.
If you have any questions regarding scaling with graphs either let us know in the comments below or reach out to us via hackers@arangodb.com.
Continue Reading
Early Bird Sign-up Open for ArangoDB Managed Service
Get the latest tutorials, blog posts and news: