
ArangoDB 3.7 – A Big Step Forward for Multi-Model
Estimated reading time: 7 minutes

When our founders realized that data models can be features, we at ArangoDB set ourselves the big goal of developing the most flexible database. With today’s GA release of ArangoDB 3.7, the project reached an important milestone on this journey.
Watch the the ArangoDB 3.7 Release Webinar.
Graph & Beyond – An Important Milestone for Multi-Model
Being a suitable solution for graph, document and key/value needs was our first milestone, which we reached several years ago. Providing this flexibility also at scale has been the second one, which we crossed with the ArangoDB cluster release as well as features like SmartGraphs and SatelliteCollections. We reached further milestones in 2018 and 2019 by introducing powerful text search & ranking capabilities with ArangoSearch, and launched the simplest way for running all this – ArangoDB ArangoGraph.
Today, with ArangoDB 3.7, the project reached the next important milestone. Our ArangoSearch team added many new key features like fuzzy search capabilities with ngram- and Levenshtein-based matching support to ArangoDB’s search engine, plus an enhanced phrase search. But we didn’t stop there.
With SatelliteGraphs, Disjoint SmartGraphs, parallel traversals and many additional graph database performance upgrades, we feel confident to say that ArangoDB 3.7 is now the most flexible and scalable graph database available. The new schema validation feature is just one of many extra treats the team has coded into the package.
So we would be delighted if you take ArangoDB 3.7 for a spin. Download the Enterprise Edition (free for evaluation) or Community Edition to test drive all the new stuff.
ArangoSearch – We LIKE it Fuzzy
People type with two thumbs when searching on mobile. Scientists have to deal with non-exact matching searches. Bioinformaticians deal with variations in DNA sequences encoded as an insanely long string.
Despite these realities, what you want in your applications is to provide relevant search results for your users. Based on n-gram similarity or Levenshtein distance, you can now deliver fine-grained search results with the new fuzzy search capabilities in ArangoSearch. And you can do this also at *buzzword alert* web scale.
Fuzzy Search Examples with n-gram and Levenshtein
N-gram
FOR d IN v_imdb
SEARCH NGRAM_MATCH(
d.description,
'rodo Same goo to Moardoor',
0.6,
'fuzzy_search_bigram' )
SORT BM25(d) DESC
LIMIT 1
RETURN d.title-> Will find “Lord of the Rings” in the IMDB movie database
Levenshtein
FOR d IN v_imdb
SEARCH LEVENSHTEIN_MATCH(
d.title, 'Galxy',
2, true, 3),
SORT BM25(d) DESC
LIMIT 10
RETURN d.title-> Will find all movies containing “Galaxy” in the title
You can directly dive into the new search capabilities with this interactive tutorial guiding you through the various options and providing some background infos about when to use which fuzzy search algorithms.
For those interested in our journey to fuzzy search, feel free to check out this article.
In addition, ArangoSearch now also supports the LIKE-operator with the new Wildcard Matching.
The following queries match “foobar”, “fooANYTHINGbor” etc.
FOR doc IN viewName
SEARCH LIKE(doc.text, "foo%b_r")
RETURN doc.textFOR doc IN viewName
SEARCH doc.text LIKE "foo%b_r"
RETURN doc.textEnhanced phrase and proximity search allows to combine phrase queries with fuzzy and wildcard matching to perform really complex full-text queries and even generate them on the fly:
FOR doc IN viewName
SEARCH PHRASE(
doc.text,
[
{ LEVENSHTEIN_MATCH : [ "queck", 1, false] }, // match "quick"
{ WILDCARD: "b%n%" }, // match "brown", "bunny" etc
"fox"
],
"text_en")
RETURN doc.text ArangoSearch in 3.7 comes with many other upgrades and vast performance improvements
- storing attribute values directly in the index allows to drastically reduce load to the storage engine by reading only a subset of attributes that are necessary for a query
- improved late document materialization with stored values
- improved multilingual support for 15 additional languages
- and many performance improvements like new SIMD-based index format for much faster queries
In the release notes you’ll find all details about ArangoSearch upgrades.
The Most Flexible Graph Database – At Any Scale
ArangoDB has always been one of the very few graph databases capable of scaling vertically (thanks C++) and, more importantly, horizontally while keeping graph queries fast.
SmartGraphs has been the key feature for enabling horizontal scale while preserving high end performance of graph queries. With SatelliteGraphs and Disjoint SmartGraphs in ArangoDB 3.7, we take this flexibility a big step further.
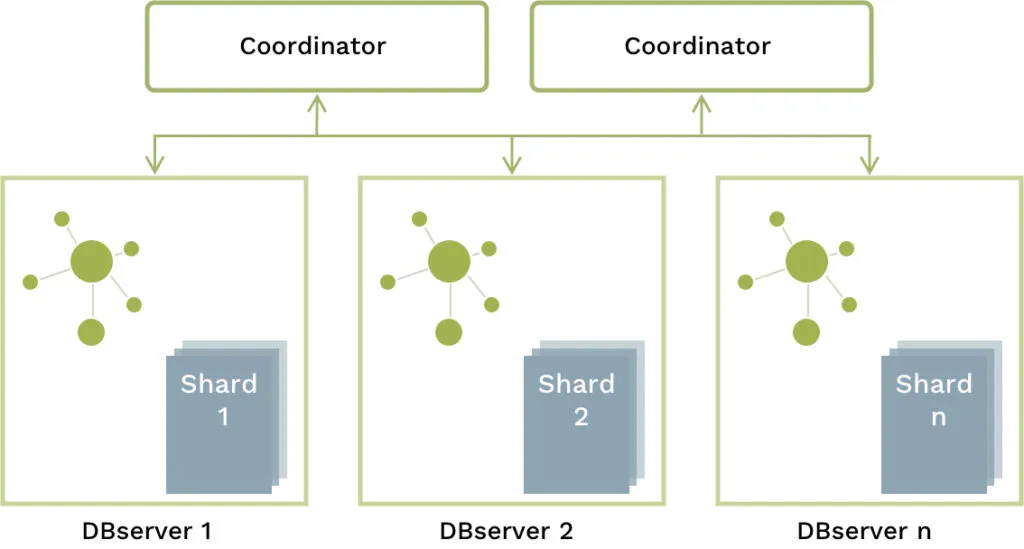
SatelliteGraphs (Enterprise Edition)
SatelliteGraphs is a new way to organize large datasets in your cluster for optimal performance of graph, as well as multi-model queries (including for example joins).
Imagine an enterprise permission application that manages access to your organization’s documents, or an IoT analytics application where you want to run network analytics including sensor data. In such projects you want to shard the large document/fact collection but replicate the smaller graphs to each machine for local query execution and without network latency. SatelliteGraphs is the perfect solution for these use cases.
Disjoint SmartGraphs (Enterprise Edition)
SmartGraphs let you distribute large, highly interconnected graphs to a cluster while keeping the performance high – perfect for social network analytics, cybersecurity applications, customer 360 initiatives, Knowledge Graph use cases and much more.
But there are cases when you have large graphs which are more hierarchical by nature and you need another approach for even better performance. For those situations we extended the capabilities of SmartGraphs and designed Disjoint SmartGraphs.
Think about large Bill-of-Materials in manufacturing, complex Identity & Access Management use cases or large IT network infrastructures — here you might find graphs which have a more hierarchical nature with clearly definable branches without relations between them.
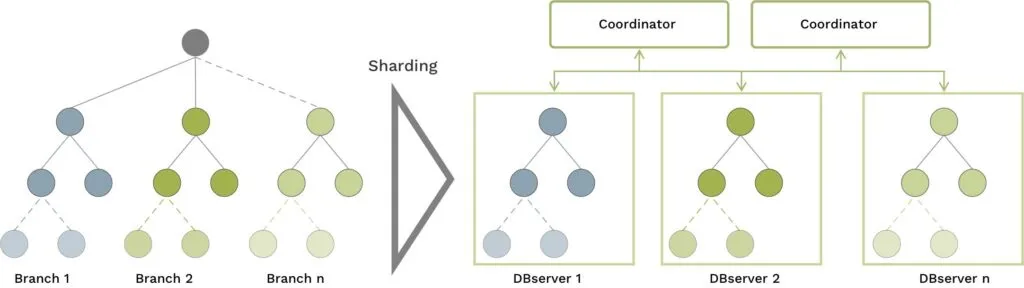
Disjoint SmartGraphs enables the automatic sharding of these branches and prohibits edges connecting branches. This allows the query optimizer to push the whole query execution down to the DBserver and greatly improve performance for graph queries like traversals, pattern matching, shortest and k-shortest paths.
Parallel Graph Traversals (Enterprise Edition)
Graph query performance has greatly improved with 3.7 across the board with many optimizations available also in the open-source Community Edition of ArangoDB.
Yet, the Enterprise Edition comes with a special treat: Parallel Graph Traversals let you make use of all cores of a server and you can specify the level of parallelism via the options of the traversal query. Currently available for single instance and OneShard clusters, first beta customers report significant performance gains for their use cases. We definitely recommend to take this new Enterprise feature for a serious spin.
With all these new capabilities and the feature richness of ArangoDB, we feel confident to say that ArangoDB is now the most flexible graph database today.
Additional Features From the Relational Realm
ACID transactions, complex filters or JOINs have been supported in ArangoDB for several years now, making it possible to transfer your data model 1:1 from relational databases to ArangoDB.
Having a flexible schema is great to easily adapt to changing requirements in your data model but at some point you might want to focus more on data consistency. With 3.7, there is now an integrated Schema Validation (draft-4) in ArangoDB which can be configured on collection level.
You can validate incoming data but also already existing data and test if it fits to your defined JSON schema. Schema validation is an opt-in feature, so it is up to database administrators to define schemas for collections where it makes sense, and keep the freedom and flexibility of a schema-less database for other use cases.
You can do a simple test drive with the new schema validation in this tutorial.
Eyes on Security
The Community and Enterprise Edition already included many features to keep your data safe. Encryption on transit, at rest and encrypted backups provide a strong shield against attackers. Auditing allows for detailed access tracing, and enhanced data masking lets you export production data securely to staging and testing environments, by masking sensible data while keeping its original structure.
In ArangoDB 3.7 you can now also rotate JWT tokens and TLS certificates without server restart (hot reload).
…and much more in ArangoDB 3.7
There are so many new goodies in ArangoDB 3.7 that we can’t dedicate a whole paragraph to each one. But nonetheless, some might find these additional features and improvements very useful:
| HTTP/2 Support | AQL Datetime parsing (ISO 8601) |
| Server Name Indication (Enterprise) | Incremental Plan Updates (Cluster) |
| Insert-Update and Insert-Ignore | Parallel Move Shards (Cluster) |
| Foxx Security Improvements | Cluster Metrics API (Prometheus compatible) |
We hope ArangoDB 3.7 has something useful for you and your project.
If you are new to ArangoDB, you might want to check out our free course “Getting Started With ArangoDB” on Udemy
Is a feature still missing for you? Let us know via hackers@arangodb.com or join over 3000 fellow Arangos on Slack
Continue Reading
Welcome Matt Ekstrom, CRO, and Jörg Schad, Head of Engineering & Machine Learning!
RC7 of ArangoDB 3.5: Streaming Transactions API
RC4 of ArangoDB 3.5: Configurable Analyzers & other ArangoSearch Upgrades
Get the latest tutorials, blog posts and news: