
Introducing the ArangoDB-PyG Adapter
Estimated reading time: 10 minutes
We are proud to announce the GA 1.0 release of the ArangoDB-PyG Adapter!
The ArangoDB-PyG Adapter exports Graphs from ArangoDB, the multi-model database for graph & beyond, into PyTorch Geometric (PyG), a PyTorch-based Graph Neural Network library, and vice-versa.
On July 29 2022, we introduced the first release of the PyTorch Geometric Adapter to the ArangoML community. We are proud to have PyG as the fourth member of our ArangoDB Adapter Family. You can expect the same developer-friendly adapter options and a helpful getting-started guide via Jupyter Notebook, and stay tuned for an upcoming Lunch & Learn session!
This blog post will serve as a walkthrough of the ArangoDB-PyG Adapter, via its official Jupyter Notebook.
(more…)
Integrate ArangoDB with PyTorch Geometric to Build Recommendation Systems
Estimated reading time: 20 minutes
In this blog post, we will build a complete movie recommendation application using ArangoDB and PyTorch Geometric. We will tackle the challenge of building a movie recommendation application by transforming it into the task of link prediction. Our goal is to predict missing links between a user and the movies they have not watched yet.
(more…)
ArangoSync: A Recipe for Reliability
Estimated reading time: 18 minutes
A detailed journey into deploying a DC2DC replicated environment
When we thought about all the things we wanted to share with our users there were obviously a lot of topics to choose from. Our Enterprise feature; ArangoSync was one of the topics that we have talked about frequently and we have also seen that our customers are keen to implement this in their environments. Mostly because of the secure requirements of having an ArangoDB cluster and all of its data located in multiple locations in case of a severe outage.
This blog post will help you set up and run an ArangoDB DC2DC environment and will guide you through all the necessary steps. By following the steps described you’ll be sure to end up with a production grade deployment of two ArangoDB clusters communicating with each other with datacenter to datacenter replication.
(more…)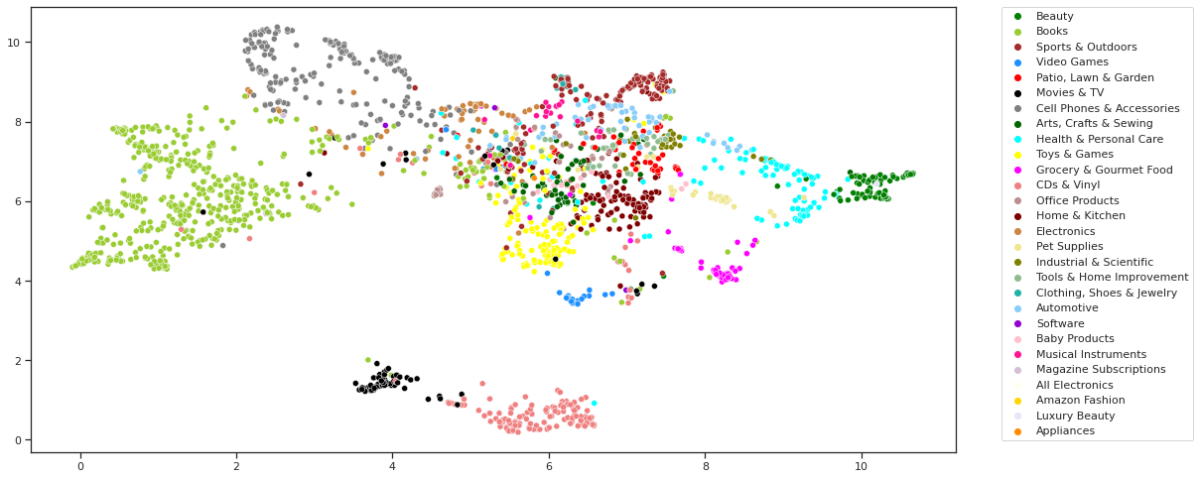
A Comprehensive Case-Study of GraphSage using PyTorchGeometric and Open-Graph-Benchmark
Estimated reading time: 15 minute
This blog post provides a comprehensive study on the theoretical and practical understanding of GraphSage, this notebook will cover:
- What is GraphSage
- Neighbourhood Sampling
- Getting Hands-on Experience with GraphSage and PyTorch Geometric Library
- Open-Graph-Benchmark’s Amazon Product Recommendation Dataset
- Creating and Saving a model
- Generating Graph Embeddings Visualizations and Observations

Community Notebook Challenge
Calling all Community Members! 🥑
Today we are excited to announce our Community Notebook Challenge.
What is our Notebook Challenge you ask? Well, this blog post is going to catch you up to speed and get you excited to participate and have the chance to win the grand prize: a pair of custom Apple Airpod Pros.
(more…)
Detecting Complex Fraud Patterns with ArangoDB
Introduction
This article presents a case study of using AQL queries for detecting complex money laundering and financial crime patterns. While there have been multiple publications about the advantages of graph databases for fraud detection use cases, few of them provide concrete examples of implementing detection of complex fraud patterns that would work in real-world scenarios.
This case study is based on a third-party transaction data generator, which is designed to simulate realistic transaction graphs of any size. The generator disguises complex financial fraud patterns of two kinds:
- Circular money flows: a big amount of money is going through different nodes and comes back to the source node.
- Indirect money transfers: a big amount of money is sent from source node to a target node over a multi-layered network of intermediate accounts.
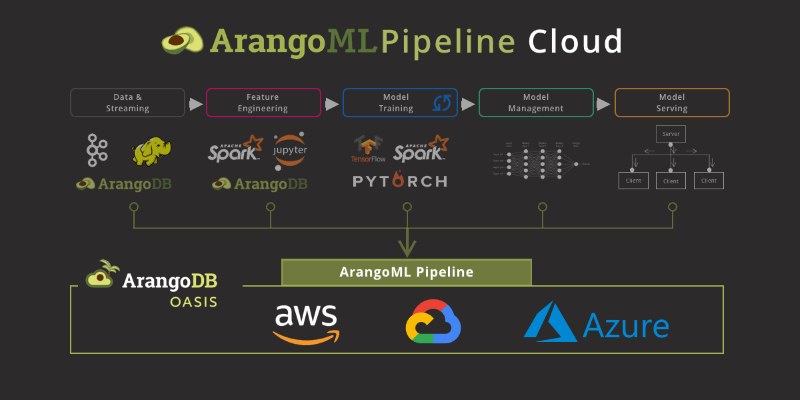
ArangoML Series: Intro to NetworkX Adapter
Estimated reading time: 3 minutes
This post is the fifth in a series of posts introducing the ArangoML features and tools. This post introduces the NetworkX adapter, which makes it easy to analyze your graphs stored in ArangoDB with NetworkX.
In this post we:
- Briefly introduce NetworkX
- Explore the IMDB user rating dataset
- Showcase the ArangoDB integration of NetworkX
- Explore the centrality measures of the data using NetworkX
- Store the experiment with arangopipe
This notebook is just a slice of the full-sized notebook available in the ArangoDB NetworkX adapter repository. It is summarized here to better fit the blog post format and provide a quick introduction to using the NetworkX adapter.
Best Practices for AQL Graph Queries
Estimated reading time: 8 minutes

The ArangoDB Query Language(AQL) was designed to accomplish a few important goals, including:
- Be a human-readable query language
- Client independency
- Support complex query patterns
- Support all ArangoDB data models with one language
The goal of this guide is to ensure Read more
Performance analysis with pyArango: Part III Measuring possible capacity with usage Scenarios
Setting up Datacenter to Datacenter Replication in ArangoDB
Please note that this tutorial is valid for the ArangoDB 3.3 milestone 1 version of DC to DC replication!
Interested in trying out ArangoDB? Fire up your cluster in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here
This milestone release contains data-center to data-center replication as an enterprise feature. This is a preview of the upcoming 3.3 release and is not considered production-ready.
In order to prepare for a major disaster, you can setup a backup data center that will take over operations if the primary data center goes down. For a server failure, the resilience features of ArangoDB can be used. Data center to data center is used to handle the failure of a complete data center.
Data is transported between data-centers using a message queue. The current implementation uses Apache Kafka as message queue. Apache Kafka is a commonly used open source message queue which is capable of handling multiple data-centers. However, the ArangoDB replication is not tied to Apache Kafka. We plan to support different message queues systems in the future.
The following contains a high-level description how to setup data-center to data-center replication. Detailed instructions for specific operating systems will follow shortly. Read more
Get the latest tutorials,
blog posts and news: