
ArangoDB v3.9 reached End of Life (EOL) and is no longer supported.
This documentation is outdated. Please see the most recent version at docs.arangodb.com
Graph traversals in AQL
Syntax
There are two slightly different syntaxes for traversals in AQL, one for
- named graphs and another to
- specify a set of edge collections (anonymous graph).
Working with named graphs
[WITH vertexCollection1[, vertexCollection2[, ...vertexCollectionN]]]
FOR vertex[, edge[, path]]
IN [min[..max]]
OUTBOUND|INBOUND|ANY startVertex
GRAPH graphName
[PRUNE pruneCondition]
[OPTIONS options]
WITH: optional for single server instances, but required for graph traversals in a cluster.- collections (collection, repeatable): list of vertex collections that will be involved in the traversal
FOR: emits up to three variables:- vertex (object): the current vertex in a traversal
- edge (object, optional): the current edge in a traversal
- path (object, optional): representation of the current path with
two members:
vertices: an array of all vertices on this pathedges: an array of all edges on this path
INmin..max: the minimal and maximal depth for the traversal:- min (number, optional): edges and vertices returned by this query will start at the traversal depth of min (thus edges and vertices below will not be returned). If not specified, it defaults to 1. The minimal possible value is 0.
- max (number, optional): up to max length paths are traversed. If omitted, max defaults to min. Thus only the vertices and edges in the range of min are returned. max can not be specified without min.
OUTBOUND|INBOUND|ANY: follow outgoing, incoming, or edges pointing in either direction in the traversal; Please note that this can’t be replaced by a bind parameter.- startVertex (string|object): a vertex where the traversal will originate from.
This can be specified in the form of an ID string or in the form of a document
with the attribute
_id. All other values will lead to a warning and an empty result. If the specified document does not exist, the result is empty as well and there is no warning. GRAPHgraphName (string): the name identifying the named graph. Its vertex and edge collections will be looked up. Note that the graph name is like a regular string, hence it must be enclosed by quote marks.PRUNEcondition (AQL condition, optional): A condition, like in a FILTER statement, which will be evaluated in every step of the traversal, as early as possible. The semantics of this condition is as follows:- If the condition evaluates to
truethis path will be considered as a result, it might still be post filtered or ignored due to depth constraints. However the search will not continue from this path, namely there will be no result having this path as a prefix. e.g.: Take the path:(A) -> (B) -> (C)starting atAand PRUNE onBwill result in(A)and(A) -> (B)being valid paths, and(A) -> (B) -> (C)not returned, it got pruned on B. - If the condition evaluates to
falsewe will continue our search beyond this path. There is only onePRUNEcondition possible, but it can contain an arbitrary amount ofANDorORstatements. Also note that you can use the output variables of this traversal in thePRUNE, as well as all variables defined before this Traversal statement.
- If the condition evaluates to
OPTIONSoptions (object, optional): used to modify the execution of the traversal. Only the following attributes have an effect, all others are ignored:- order (string): optionally specify which traversal algorithm to use
"bfs"– the traversal will be executed breadth-first. The results will first contain all vertices at depth 1, then all vertices at depth 2 and so on."dfs"(default) – the traversal will be executed depth-first. It will first return all paths from min depth to max depth for one vertex at depth 1, then for the next vertex at depth 1 and so on."weighted"- the traversal will be a weighted traversal (introduced in v3.8.0). Paths are enumerated with increasing cost. Also seeweightAttributeanddefaultWeight. A returned path has an additional attributeweightcontaining the cost of the path after every step. The order of paths having the same cost is non-deterministic. Negative weights are not supported and will abort the query with an error.
- bfs (bool): deprecated, use
order: "bfs"instead. - uniqueVertices (string): optionally ensure vertex uniqueness
"path"– it is guaranteed that there is no path returned with a duplicate vertex"global"– it is guaranteed that each vertex is visited at most once during the traversal, no matter how many paths lead from the start vertex to this one. If you start with amin depth > 1a vertex that was found before min depth might not be returned at all (it still might be part of a path). It is required to setorder: "bfs"ororder: "weighted"because with depth-first search the results would be unpredictable. Note: Using this configuration the result is not deterministic any more. If there are multiple paths from startVertex to vertex, one of those is picked. In case of aweightedtraversal, the path with the lowest weight is picked, but in case of equal weights it is undefined which one is chosen."none"(default) – no uniqueness check is applied on vertices
- uniqueEdges (string): optionally ensure edge uniqueness
"path"(default) – it is guaranteed that there is no path returned with a duplicate edge"none"– no uniqueness check is applied on edges. Note: Using this configuration the traversal will follow edges in cycles.
- edgeCollections (string|array): Optionally restrict edge
collections the traversal may visit (introduced in v3.7.0). If omitted,
or an empty array is specified, then there are no restrictions.
- A string parameter is treated as the equivalent of an array with a single element.
- Each element of the array should be a string containing the name of an edge collection.
- vertexCollections (string|array): Optionally restrict vertex
collections the traversal may visit (introduced in v3.7.0). If omitted,
or an empty array is specified, then there are no restrictions.
- A string parameter is treated as the equivalent of an array with a single element.
- Each element of the array should be a string containing the name of a vertex collection.
- The starting vertex is always allowed, even if it does not belong to one of the collections specified by a restriction.
-
parallelism (number, optional): Optionally parallelize traversal execution (introduced in v3.7.1). If omitted or set to a value of
1, traversal execution is not parallelized. If set to a value greater than1, then up to that many worker threads can be used for concurrently executing the traversal. The value is capped by the number of available cores on the target machine.Parallelizing a traversal is normally useful when there are many inputs (start vertices) that the nested traversal can work on concurrently. This is often the case when a nested traversal is fed with several tens of thousands of start vertices, which can then be distributed randomly to worker threads for parallel execution.
Traversal parallelization is only available in the Enterprise Edition, and limited to traversals in single server deployments and to cluster traversals that are running in a OneShard setup. Cluster traversals that run on a Coordinator node and SmartGraph traversals are currently not parallelized, even if the options is specified.
- weightAttribute (string, optional): Specifies the name of an attribute
that is used to look up the weight of an edge. If no attribute is specified
or if it is not present in the edge document then the
defaultWeightis used. The attribute value must not be negative. - defaultWeight (number, optional): Specifies the default weight of an edge.
The value must not be negative. The default value is
1.
- order (string): optionally specify which traversal algorithm to use
Weighted traversals do not support negative weights. If a document attribute (as specified by weightAttribute) with a negative value is encountered during traversal, or if defaultWeight is set to a negative number, then the query is aborted with an error.
Working with collection sets
[WITH vertexCollection1[, vertexCollection2[, ...vertexCollectionN]]]
FOR vertex[, edge[, path]]
IN [min[..max]]
OUTBOUND|INBOUND|ANY startVertex
edgeCollection1, ..., edgeCollectionN
[PRUNE pruneCondition]
[OPTIONS options]
Instead of GRAPH graphName you may specify a list of edge collections. Vertex
collections are determined by the edges in the edge collections. The traversal
options are the same as with the named graph variant,
though the edgeCollections restriction option is redundant in this case.
If the same edge collection is specified multiple times, it will behave as if it were specified only once. Specifying the same edge collection is only allowed when the collections do not have conflicting traversal directions.
ArangoSearch Views cannot be used as edge collections.
Traversing in mixed directions
For traversals with a list of edge collections you can optionally specify the
direction for some of the edge collections. Say for example you have three edge
collections edges1, edges2 and edges3, where in edges2 the direction has
no relevance but in edges1 and edges3 the direction should be taken into account.
In this case you can use OUTBOUND as general traversal direction and ANY
specifically for edges2 as follows:
FOR vertex IN OUTBOUND
startVertex
edges1, ANY edges2, edges3
All collections in the list that do not specify their own direction will use the
direction defined after IN. This allows to use a different direction for each
collection in your traversal.
Graph traversals in a cluster
Due to the nature of graphs, edges may reference vertices from arbitrary collections. Following the paths can thus involve documents from various collections and it is not possible to predict which will be visited in a traversal. Which collections need to be loaded by the graph engine can only be determined at run time.
Use the WITH statement to specify the collections you
expect to be involved. This is required for traversals using collection sets
in cluster deployments.
Using filters and the explainer to extrapolate the costs
All three variables emitted by the traversals might as well be used in filter statements. For some of these filter statements the optimizer can detect that it is possible to prune paths of traversals earlier, hence filtered results will not be emitted to the variables in the first place. This may significantly improve the performance of your query. Whenever a filter is not fulfilled, the complete set of vertex, edge and path will be skipped. All paths with a length greater than max will never be computed.
In the current state, AND combined filters can be optimized, but OR
combined filters cannot.
The following examples are based on the traversal graph.
Pruning
Introduced in: v3.4.5
Pruning is the easiest variant to formulate conditions to reduce the amount of data to be checked during a search. So it allows to improve query performance and reduces the amount of overhead generated by the query.
You can use the vertex, edge, and path variables emitted by the traversal in a
prune expression, as well as all other variables defined before the FOR operation.
You can use AQL functions in prune expressions but only those that can be executed on DB-Servers, regardless of your deployment type. The following functions cannot be used in the expression:
CALL()APPLY()DOCUMENT()V8()SCHEMA_GET()SCHEMA_VALIDATE()VERSION()COLLECTIONS()CURRENT_USER()CURRENT_DATABASE()COLLECTION_COUNT()NEAR()WITHIN()WITHIN_RECTANGLE()FULLTEXT()- User-defined functions (UDFs)
Examples:
This will search until it sees an edge having theTruth == true.
The path with this edge will be returned, the search will not
continue after this edge.
Namely all responses either have no edge with theTruth == true
or the last edge on the path has theTruth == true.
This will search for all paths from the source circles/A to the vertex circles/G.
This is done with first the PRUNE which makes sure we stop search as soon as we have found
G and we will not go beyond G and via a loop return to it.
With the second filter, we remove all paths that do not end in G namely
all shorter ones that have not been cut out by prune.
Hence the list of all paths from A to G are returned.
Note you can also prune as soon as you reach a certain collection with the following example:
FOR v, e, p IN 1..5 OUTBOUND 'circles/A' GRAPH 'traversalGraph'
PRUNE IS_SAME_COLLECTION('circles', v)
RETURN { vertices: p.vertices[*]._key, edges: p.edges[*].label }
[]
The edge emitted for the starting vertex is null. Keep this in mind when you write PRUNE conditions involving the edge variable. A PRUNE condition like edge.label != 'foo' is undesirably true at depth 0 and thus terminates the traversal too early. A construction like (!IS_NULL(edge) AND edge.label != 'foo') can be used to avoid it.
There is also the option to store the PRUNE condition as a variable, as in the
following example:
This will store the PRUNE condition v._key == 'G' in the variable
pruneCondition. Later on, it will be used as the condition for FILTER to
avoid retyping the condition that is the same as in PRUNE.
Filtering on paths
Filtering on paths allows for the second most powerful filtering and may have the second highest impact on performance. Using the path variable you can filter on specific iteration depths. You can filter for absolute positions in the path by specifying a positive number (which then qualifies for the optimizations), or relative positions to the end of the path by specifying a negative number.
Filtering edges on the path
will filter all paths where the start edge (index 0) has the attribute theTruth equal to true. The resulting paths will be up to 5 items long.
Filtering vertices on the path
Similar to filtering the edges on the path you can also filter the vertices:
Combining several filters
And of course you can combine these filters in any way you like:
The query will filter all paths where the first edge has the attribute theTruth equal to true, the first vertex is “G” and the second edge has the attribute theFalse equal to false. The resulting paths will be up to 5 items long.
Note: Although we have defined a min of 1, we will only get results of depth 2. This is because for all results in depth 1 the second edge does not exist and hence cannot fulfill the condition here.
Filter on the entire path
With the help of array comparison operators filters can also be defined
on the entire path, like ALL edges should have theTruth == true:
Or NONE of the edges should have theTruth == true:
FOR v, e, p IN 1..5 OUTBOUND 'circles/A' GRAPH 'traversalGraph'
FILTER p.edges[*].theTruth NONE == true
RETURN { vertices: p.vertices[*]._key, edges: p.edges[*].label }
[]
Both examples above are recognized by the optimizer and can potentially use other indexes than the edge index.
It is also possible to define that at least one edge on the path has to fulfill the condition:
It is guaranteed that at least one, but potentially more edges fulfill the condition. All of the above filters can be defined on vertices in the exact same way.
Filtering on the path vs. filtering on vertices or edges
Filtering on the path influences the Iteration on your graph. If certain conditions aren’t met, the traversal may stop continuing along this path.
In contrast filters on vertex or edge only express whether you’re interested in the actual value of these
documents. Thus, it influences the list of returned documents (if you return v or e) similar
as specifying a non-null min value. If you specify a min value of 2, the traversal over the first
two nodes of these paths has to be executed - you just won’t see them in your result array.
Similar are filters on vertices or edges - the traverser has to walk along these nodes, since you may be interested in documents further down the path.
Examples
We will create a simple symmetric traversal demonstration graph:
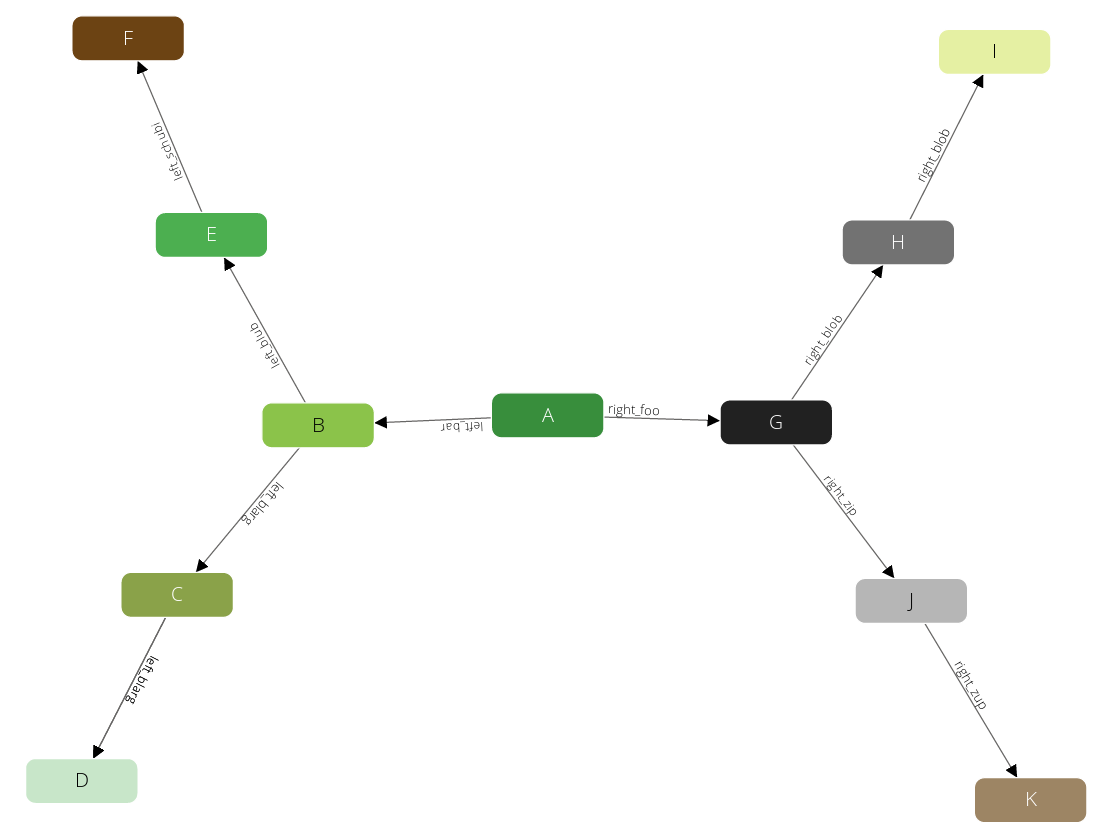
To get started we select the full graph. For better overview we only return the vertex IDs:
We can nicely see that it is heading for the first outer vertex, then goes back to the branch to descend into the next tree. After that it returns to our start node, to descend again. As we can see both queries return the same result, the first one uses the named graph, the second uses the edge collections directly.
Now we only want the elements of a specific depth (min = max = 2), the ones that are right behind the fork:
As you can see, we can express this in two ways: with or without max parameter in the expression.
Filter examples
Now let’s start to add some filters. We want to cut of the branch on the right side of the graph, we may filter in two ways:
- we know the vertex at depth 1 has
_key==G - we know the
labelattribute of the edge connecting A to G isright_foo
As we can see all vertices behind G are skipped in both queries.
The first filters on the vertex _key, the second on an edge label.
Note again, as soon as a filter is not fulfilled for any of the three elements
v, e or p, the complete set of these will be excluded from the result.
We also may combine several filters, for instance to filter out the right branch (G), and the E branch:
FOR v,e,p IN 1..3 OUTBOUND 'circles/A' GRAPH 'traversalGraph'
FILTER p.vertices[1]._key != 'G'
FILTER p.edges[1].label != 'left_blub'
RETURN v._key
[
"B",
"C",
"D"
]
FOR v,e,p IN 1..3 OUTBOUND 'circles/A' GRAPH 'traversalGraph'
FILTER p.vertices[1]._key != 'G' AND p.edges[1].label != 'left_blub'
RETURN v._key
[
"B",
"C",
"D"
]
As you can see, combining two FILTER statements with an AND has the same result.
Comparing OUTBOUND / INBOUND / ANY
All our previous examples traversed the graph in OUTBOUND edge direction.
You may however want to also traverse in reverse direction (INBOUND) or
both (ANY). Since circles/A only has outbound edges, we start our queries
from circles/E:
FOR v IN 1..3 OUTBOUND 'circles/E' GRAPH 'traversalGraph'
RETURN v._key
[
"F"
]
FOR v IN 1..3 INBOUND 'circles/E' GRAPH 'traversalGraph'
RETURN v._key
[
"B",
"A"
]
The first traversal will only walk in the forward (OUTBOUND) direction.
Therefore from E we only can see F. Walking in reverse direction
(INBOUND), we see the path to A: B → A.
Walking in forward and reverse direction (ANY) we can see a more diverse result.
First of all, we see the simple paths to F and A. However, these vertices
have edges in other directions and they will be traversed.
Note: The traverser may use identical edges multiple times. For instance, if it walks from E to F, it will continue to walk from F to E using the same edge once again. Due to this we will see duplicate nodes in the result.
Please note that the direction can’t be passed in by a bind parameter.
Use the AQL explainer for optimizations
Now let’s have a look what the optimizer does behind the curtain and inspect traversal queries using the explainer:
We now see two queries: In one we add a variable localScopeVar, which is outside the scope of the traversal itself - it is not known inside of the traverser. Therefore, this filter can only be executed after the traversal, which may be undesired in large graphs. The second query on the other hand only operates on the path, and therefore this condition can be used during the execution of the traversal. Paths that are filtered out by this condition won’t be processed at all.
And finally clean it up again:
arangosh> var examples = require("@arangodb/graph-examples/example-graph.js");
arangosh> examples.dropGraph("traversalGraph");
(Empty output)
If this traversal is not powerful enough for your needs, like you cannot describe your conditions as AQL filter statements, then you might want to have a look at manually crafted traversers.
Also see how to combine graph traversals.