
ArangoDB v3.8 reached End of Life (EOL) and is no longer supported.
This documentation is outdated. Please see the most recent version at docs.arangodb.com
Active Failover Architecture
An Active Failover is defined as:
- One ArangoDB Single-Server instance which is read / writable by clients called Leader
- One or more ArangoDB Single-Server instances, which are passive and not writable called Followers, which asynchronously replicate data from the Leader
- At least one Agency acting as a “witness” to determine which server becomes the leader in a failure situation
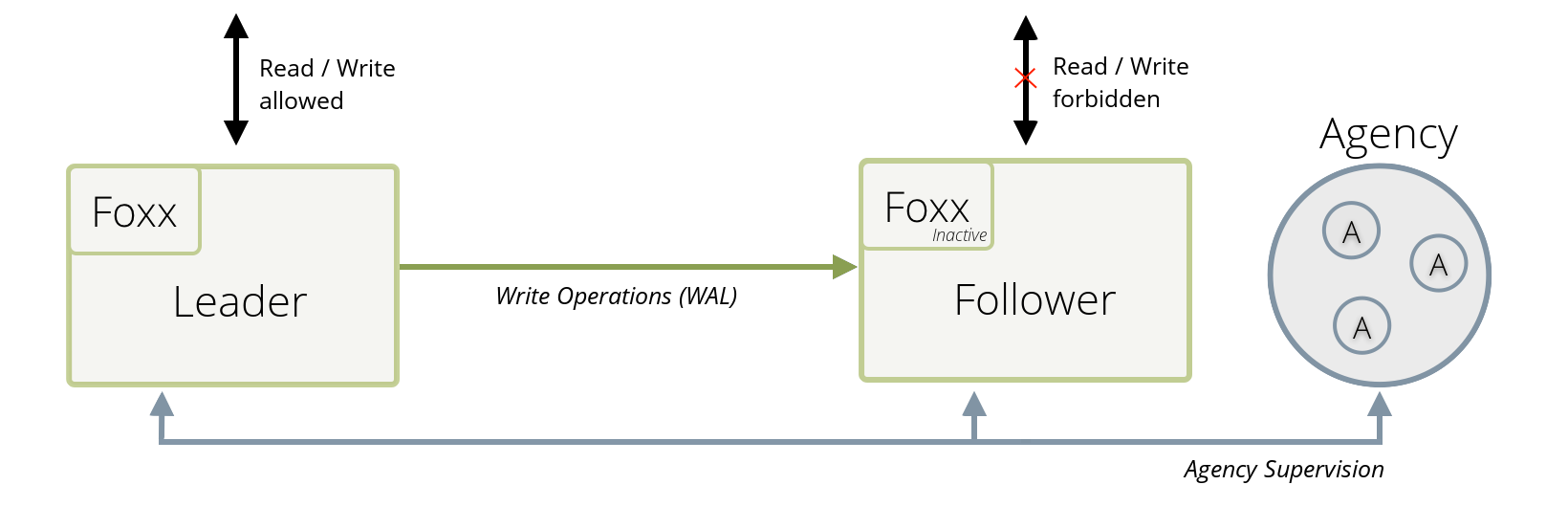
The advantage of the Active Failover compared to the traditional Leader/Follower setup is that there is an active third party, the Agency which observes and supervises all involved server processes. Follower instances can rely on the Agency to determine the correct Leader server. From an operational point of view, one advantage is that the failover, in case the Leader goes down, is automatic. An additional operational advantage is that there is no need to start a replication applier manually.
The Active Failover setup is made resilient by the fact that all the official ArangoDB drivers can automatically determine the correct leader server and redirect requests appropriately. Furthermore Foxx Services do also automatically perform a failover: should the leader instance fail (which is also the Foxxmaster) the newly elected leader will reinstall all Foxx services and resume executing queued Foxx tasks. Database users which were created on the leader will also be valid on the newly elected leader (always depending on the condition that they were synced already).
Consider the case for two arangod instances. The two servers are connected via server wide (global) asynchronous replication. One of the servers is elected Leader, and the other one is made a Follower automatically. At startup, the two servers race for the leadership position. This happens through the Agency locking mechanism (which means that the Agency needs to be available at server start). You can control which server will become Leader by starting it earlier than other server instances in the beginning.
The Follower will automatically start replication from the Leader for all available databases, using the server-level replication introduced in v. 3.3.
When the Leader goes down, this is automatically detected by the Agency instance, which is also started in this mode. This instance will make the previous follower stop its replication and make it the new Leader.
The different instances participating in an Active Failover setup are supposed to be run in the same Data Center (DC), with a reliable high-speed network connection between all the machines participating in the Active Failover setup.
Multi-datacenter Active Failover setups are currently not supported.
A multi-datacenter solution currently supported is the Datacenter-to-Datacenter Replication (DC2DC) among ArangoDB Clusters. See DC2DC chapter for details.
Operative Behavior
In contrast to the normal behavior of a single-server instance, the Active-Failover mode will change the behavior of ArangoDB in some situations.
The Follower will always deny write requests from client applications.
Read requests are only permitted if the requests is marked with the
X-Arango-Allow-Dirty-Read: true header, otherwise they are denied, too.
Only the replication itself is allowed to access the follower’s data until the
follower becomes a new Leader (should a failover happen).
When sending a request to read or write data on a Follower, the Follower will
respond with HTTP 503 (Service unavailable) and provide the address of
the current Leader. Client applications and drivers can use this information to
then make a follow-up request to the proper Leader:
HTTP/1.1 503 Service Unavailable
X-Arango-Endpoint: http://[::1]:8531
....
Client applications can also detect who the current Leader and the Followers
are by calling the /_api/cluster/endpoints REST API. This API is accessible
on Leader and Followers alike.
Reading from Followers
Followers in the active-failover setup are in read-only mode. It is possible to read from these
followers by adding a X-Arango-Allow-Dirty-Read: true header on each request. Responses will then automatically
contain the X-Arango-Potential-Dirty-Read: true header so that clients can reject accidental dirty reads.
Depending on the driver support for your specific programming language, you should be able to enable this option.
Tooling Support
The tool ArangoDB Starter supports starting two servers with asynchronous replication and failover out of the box.
The arangojs driver for JavaScript, the Go driver, the Java driver, ArangoJS and
the PHP driver support active failover in case the currently accessed server endpoint
responds with HTTP 503.