
ArangoSearch architecture overview
In this article, we’re going to dive deeper into our recently released feature preview in Milestone ArangoDB 3.4 – ArangoSearch which provides a rich set of information retrieval capabilities. In particular, we’ll give you an idea of how our search engine works under the hood.
Essentially ArangoSearch consists of 2 components: A search engine and an integration layer. The former is responsible for managing the index, querying and scoring, whereas latter exposes search capabilities to the end user in a convenient way.
ArangoSearch index
Inverted Index is the heart of ArangoSearch. The index structure and index management approach are inspired by well-known search engine Lucene.
The index consists of several independent segments and the index segment itself is meant to be treated as a standalone index. Each segment contains the following components:
- Term dictionary is responsible for storing and providing fast access to all terms (and its metadata) ever seen in a segment
- Posting lists are storing and providing fast access to information about documents, term positions, payloads for each seen term
- Segment metadata is responsible for storing different segment related properties
- Tombstones contains documents that have been deleted but not yet purged from the storage
- Columnstore is responsible for storing and providing fast access to arbitrary information on per column basis
The following picture gives you a basic understanding of how ArangoSearch index logically looks like:
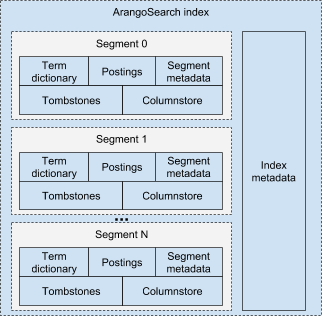
Typically, an ArangoSearch query iterates over all segments in the index, finds documents satisfying search criteria and returns them to the caller. We’re going to dive deeper into index structure and management in the upcoming articles but for now let’s talk about the integration layer.
ArangoSearch integration layer
The integration layer tries to hide all complexity behind maintaining the index and exposes all functionality via convenient ArangoDB APIs.
DML integration
ArangoDB is a multi-model database which allows you to store your data as key/value pairs, documents and graphs. Because of such native multi-model approach seamless integration of search engine becomes quite complicated.
The following scheme gives you an idea of how data appear in ArangoSearch index.
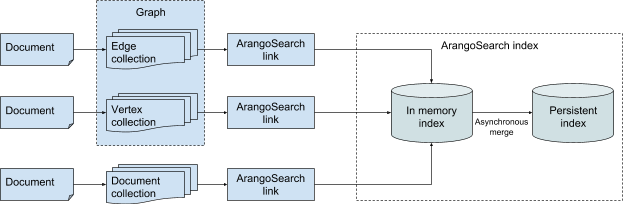
Once created a view may have arbitrary number of ArangoSearch links between collections of any type and a view. Essentially a link is a unidirectional connection from ArangoDB collection to an ArangoSearch view. The ArangoSearch link created on a collection operates like an index with the only difference that it does nothing but delegate all incoming requests to a corresponding view.
The ArangoSearch link contains information of how data is coming from a collection should be indexed, in particular:
- which fields have to be indexed (or all)
- which analyzers have to be applied to a fields
- how deep hierarchical JSON documents have to be processed
- how lists/arrays have to be indexed in terms of individual position tracking
All these properties are very important since they affect the upcoming querying phase.
Eventually read committed
In order to speed up indexing, the ArangoSearch view processes modification requests coming from ArangoSearch link on a batch basis. From time to time an asynchronous job commits accumulated data creating new index segments. Data is being visible right after the commit, so that speaking of transaction isolation, ArangoSearch view is on the eventually read committed level.
There are 2 separate indexes per each view: in-memory index and persistent index. All documents coming from the links first get into the in memory index and eventually (in asynchronous fashion) appear to be in the latter. Having 2 separate indexes is the crucial part for fast startup and recovery since ArangoSearch views don’t need to reindex all data from linked collections. Merging memory part into persistent store is also quite important since ArangoSearch view doesn’t want to consume all your RAM.
Managing data consistency
ArangoSearch view does not store any data except the “references” to documents, which means that view always relies on data in the linked collection(s). That actually obliges ArangoDB to maintain data consistency between data in collection(s) and view(s) so that in the event of a crash and following recovery an ArangoSearch view will appear to be in a consistent state.
In order to provide such guarantees, ArangoDB stores some information about the current view(s) state in WAL and uses it later for recovery.
Since ArangoSearch view eventually reads documents from linked collections within a scope of transaction it guarantees to be consistent with the data.
Removals and consolidation
ArangoSearch view handles removals in a two steps fashion pretty similar to collections in ArangoDB. Once removal request arrived, ArangoSearch view first marks document as deleted which means that particular document will be filtered out of query result. At this point document is still in the index but the data itself is a garbage. As one can imagine there will be a lot of such garbage documents eventually which causes slower queries and high memory consumption.
In order to avoid such nasty situation ArangoSearch has built-in support of index consolidation. Index consolidation is meant to be treated as the procedure of joining multiple index segments into a bigger one and removing garbage documents. Merging also reduces number of segments to traverse which is speeding up queries.
There are number of built-in consolidation policies one can choose according to its own load, e.g. based on average segment size or number of deleted documents per segment. For more information please consult our documentation.
In this article we’ve described high level architecture of recently introduced ArangoSearch views. A lot of things has been already done but even more to come: now we’re focused on AQL integration improvements and cluster-wide views support of course. Stay in touch!
Join #arangosearch channel on our Community Slack to give us feedback, improvement suggestions, if you have any questions or just to chat with us.
Get the latest tutorials, blog posts and news: