
Milestone ArangoDB 3.4:
ArangoSearch – Information retrieval with ArangoDB
For the upcoming ArangoDB 3.4 release we’ve implemented a set of information retrieval features exposed via new database object `View`. The `View` object is meant to be treated as another data source accessible via AQL and the concept itself is pretty similar to a classical “materialized” view in SQL.
While we are still working on completing the feature, you can already try our retrieval engine in the Milestone of the upcoming ArangoDB 3.4 released today.
You can download and give it a spin here:
The retrieval concept
When dealing with unstructured or semi-structured data a user usually has only a vague assumption of what she is looking for. That means when executing a query she is not only interested in datasets that just satisfy search criteria but particularly the most relevant ones.
In order to achieve that we combined two information retrieval models: boolean and generalized ranking retrieval so that each document “approved” by boolean model gets its own rank from the ranking model.
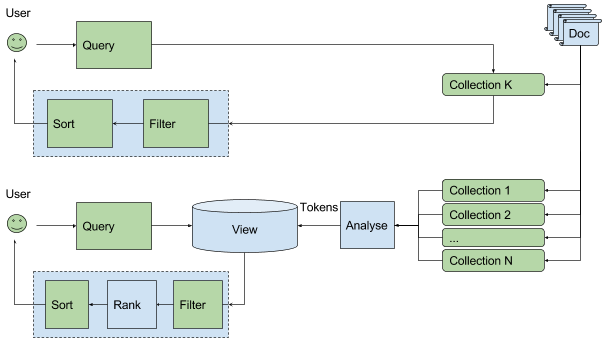
Since analysis and ranking phases are application dependent we will allow using your own plugins in future releases. As for this Milestone of the upcoming ArangoDB 3.4 release, we’ve implemented a set of analyzers and rankers that are mostly related to text processing.
Improved full-text search
For text retrieval, we use the Vector Space Model (VSM) as the ranking model. According to the model, documents and query are represented as vectors in a space formed by the “terms” of the query. The definition of “term” depends on the analysis phase of the application. Typically terms are single words, keywords or even phrases.
The document vectors that are closer to a query vector are more relevant. Practically the closeness is expressed as the cosine of the angle between two vectors, namely cosine similarity.
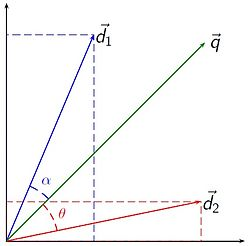
In order to define how relevant document d to the query q we have to evaluate the following expression:
cos a = (d * q) / (|d| * |q|), where
d * q is the dot product of the query vector q and document vector d,
|d| is the norm of the vector d,
|q| is the norm of the vector q
To evaluate relevance described above we have to compute vector components at first. Since we are in a space formed by the “terms” we use “term weights” as the coordinates. There are number of probability/statistical weighting models but for this Milestone release we’ve implemented two, probably the most famous schemes:
Under the hood both models rely on 2 main components:
- Term frequency (TF) in the simplest case defined as the number of times that term t occurs in document d
- Inverse document frequency (IDF) is a measure of how much information the word provides, i.e. whether the term is common or rare across all documents
Comparison with ArangoDB full-text index
The current full-text index in ArangoDB is rather limited in terms of functionality. With the upcoming ArangoDB 3.4 release, we will overcome these limitations and provide a complete text searching, matching and ranking suite. The following table contains view/index feature comparison:
| View | Full-text index | |
| Term search | + | + |
| Prefix search | + | + |
| Boolean expressions | + | Restricted |
| Range search | + | – |
| Phrase/proximity search | + | – |
| Relevance ranking | + | – |
| Pluggable analyzers | + (planned) | – |
| Pluggable rankers | + | – |
| AQL composable language construct | + | – |
| Maximum number of indexed attributes per collection | ∞ | 1 |
| Maximum number of indexed collections | ∞ | 1 |
Improved text analysis
Milestone version comes with a set of built-in text analyzers which support configurable stemming, stopwords and multilingual support (including Chinese, Russian and other languages).
If you’re interested in usage examples go through this extensive ArangoSearch tutorial or visit our documentation.
Schema agnostic indexing
Data structures like “B-tree” or “skip-list” derived from the relational world allow to seriously speedup data access by the specified attribute(s) but they have serious drawback: DBA has to predict what the user wants to find, in order to create and maintain proper indexes on collections which is not always trivial especially in schema-less world.
We utilize the simplicity of JSON and its schema manipulation in order to eliminate data delivery mismatch between the database and the user’s expectation from schema-less database.
Schema agnostic indexing is meant to be treated as the ability to index any JSON attribute at any depth or the given set of paths, allowing fast access to documents via any combination of conditions over the indexed attributes. Unlike the collections with user-defined indexes, view guarantees the best execution plan (merge join) when querying multiple attributes.
Federated retrieval
Once view has been created one may establish an arbitrary number of links between collections (of any type) and a view. That especially useful when one needs to retrieve and analyze data from multiple collections based on some conditions, e.g. find the most relevant goods or books according to a given description.
Each link is meant to be treated as the data flow from a collection to a view so that data from a collection will be accessible via the view object. ArangoSearch view gives you full control over the data coming from a particular collection allowing to specify what and how should be indexed.
Graph dualism
Since essentially graph is a combination of document and edge collections, it might be indexed by a view as well. With such approach, graph can be treated as flat and interconnected data structure simultaneously.
Dual approach allows combining information retrieval techniques with sophisticated graph traversals in order to speed up data access by a factor of magnitude, e.g. one can find the most relevant vertices according to a provided description and then do a regular traversal within a specified depth.
You can find more information regarding setting up indexing properties for view here: Extensive ArangoSearch Tutorial or documentation.
Future plans
For upcoming releases we plan to implement more exciting features:
- cluster support (of course 😉 )
- tunable query time ranking
- pluggable analyzers
- fuzzy queries (Levenstein distance)
- Jaccard similarity
- highlighting
If you are already working on a project in which other analyzers, rankers or queries are badly needed, please let us know via hackers@arangodb.com or join #arangosearch Community Slack channel. We are looking forward to your feedback!
4 Comments
Leave a Comment
Get the latest tutorials, blog posts and news:
It’s looks very cool. Is it similar to ElasticSearch? Can I just use arangodb as my backend and replace ES?
HI Andrey,
Thank you for providing ArangoSearch. I think that this would be a game changer.
I have few questions on this.
1. Can the views be formed by joining multiple collections with a common attribute?
2. Can multiple indexes (indexes on different collections) work together along with the fulltext search index.
Regards,
Sajeev
Hi Sajeev,
Thank you for such a warm welcome of our new feature.
1. Yes, multiple collections can be linked with a single ArangoSearch view instance regardless of whether there are common attributes or not. You can even have common attributes of different types.
2. What do you mean by “fulltext search index”: ArangoSearch view or full-text search index on a collection? Almost all AQL operations except the several restrictions are supported by ArangoSearch views: joins, aggregation, traversal, etc.
You also can join #arangosearch channel on slack.
Best,
Andrey
Hi Sajeev,
Thank you for such a warm welcome of our new feature.
1. Yes, multiple collections can be linked with a single ArangoSearch view instance regardless of whether there are common attributes or not. You can even have common attributes of different types.
2. What do you mean by “fulltext search index”: ArangoSearch view or full-text search index on a collection? Almost all AQL operations except the several restrictions are supported by ArangoSearch views: joins, aggregation, traversal, etc.
You also can join #arangosearch channel on slack.
Best,
Andrey